Evergreen
Senior Member (Voting Rights)
I think it would be most compelling to demonstrate the issue with the Effort task with data - people might find the logic of it hard to follow. If it can be shown from the data that the difference in the hard:easy ratio between patients and controls could be due to something else - specifically something like a difference between the groups in terms of the reward values and probabilities they were presented with - then that would be game over.
If not, then I think the key issue is the different starting point of patients and controls, in terms of it being a potentially fatiguing task for one group but not the other, render the task fundamentally invalid for comparing these groups, because it scuppers the reward system. One group has a penalty that they have to factor in when considering the rewards, the other doesn't.
If people are looking at the data, which I'm going to upload again to this message, note that HV F's data were invalid so you'll need to remove those rows.
If not, then I think the key issue is the different starting point of patients and controls, in terms of it being a potentially fatiguing task for one group but not the other, render the task fundamentally invalid for comparing these groups, because it scuppers the reward system. One group has a penalty that they have to factor in when considering the rewards, the other doesn't.
If people are looking at the data, which I'm going to upload again to this message, note that HV F's data were invalid so you'll need to remove those rows.
") Yeah, if we take those words at face value, then that would make the HV's stupid and the PI-ME/CFS participants smart. Because, if you are faced with the choice of two tasks with equal rewards and equal probabilities of receiving the reward, then why would you not choose the easy task?
Yeah, if we take those words at face value, then that would make the HV's stupid and the PI-ME/CFS participants smart. Because, if you are faced with the choice of two tasks with equal rewards and equal probabilities of receiving the reward, then why would you not choose the easy task?
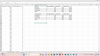
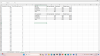
 it's exactly like broken-leg in the middle of nowhere hopscotch for a ribbon!
it's exactly like broken-leg in the middle of nowhere hopscotch for a ribbon!